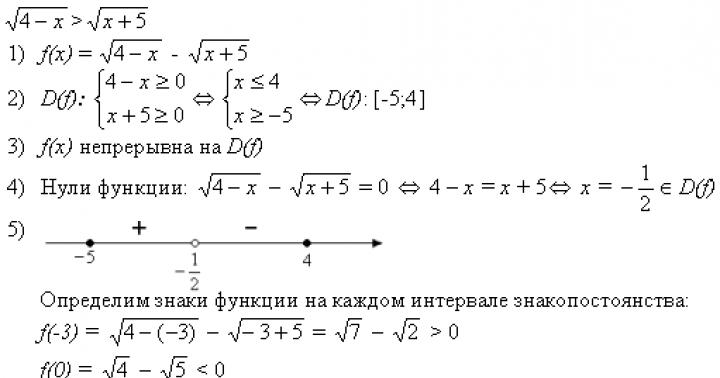Μέσο δειγματοληπτικό σφάλμα
Το σύνολο δειγματοληψίας μπορεί να διαμορφωθεί με βάση ένα ποσοτικό πρόσημο στατιστικών τιμών, καθώς και σε εναλλακτική ή αποδοτική βάση. Στην πρώτη περίπτωση, το γενικευτικό χαρακτηριστικό του δείγματος είναι δείγμα μέσου όρουυποδηλωμένη ποσότητα , και στο δεύτερο - δείγμα μεριδίουποσότητες, σημειώνονται w.Στο γενικό πληθυσμό, αντίστοιχα: γενικός μέσος όροςκαι γενικό μερίδιο του ποταμού.
Διαφορές -- και W -- σελπου ονομάζεται δειγματοληπτικό σφάλμα,που χωρίζεται σε σφάλμα εγγραφής και σε σφάλμα αντιπροσωπευτικότητας. Το πρώτο μέρος του δειγματοληπτικού σφάλματος προκύπτει λόγω λανθασμένων ή ανακριβών πληροφοριών λόγω παρανόησης της ουσίας του θέματος, απροσεξίας του καταχωρητή κατά τη συμπλήρωση ερωτηματολογίων, εντύπων κ.λπ. Είναι αρκετά εύκολο να εντοπιστεί και να διορθωθεί. Το δεύτερο μέρος του σφάλματος προκύπτει από τη συνεχή ή αυθόρμητη μη συμμόρφωση με την αρχή της τυχαίας επιλογής. Είναι δύσκολο να εντοπιστεί και να εξαλειφθεί, είναι πολύ μεγαλύτερο από το πρώτο και ως εκ τούτου δίνεται η κύρια προσοχή σε αυτό.
Η τιμή του σφάλματος δειγματοληψίας εξαρτάται από τη δομή του τελευταίου. Για παράδειγμα, εάν, κατά τον προσδιορισμό του μέσου όρου βαθμολογίας των φοιτητών ΔΕΠ, περισσότεροι αριστούχοι περιλαμβάνονται σε ένα δείγμα και περισσότεροι χαμένοι σε άλλο, τότε οι μέσες βαθμολογίες του δείγματος και τα δειγματοληπτικά σφάλματα θα είναι διαφορετικά.
Επομένως, στις στατιστικές, το μέσο σφάλμα επαναλαμβανόμενης και μη επαναλαμβανόμενης δειγματοληψίας προσδιορίζεται με τη μορφή της ειδικής τυπικής απόκλισης σύμφωνα με τους τύπους
= - αλλεπάλληλος; (1,35)
= - μη επαναλαμβανόμενο? (1,36)
όπου Dv είναι η διακύμανση του δείγματος, που προσδιορίζεται με ένα ποσοτικό πρόσημο στατιστικών τιμών σύμφωνα με τους συνήθεις τύπους από το Κεφάλαιο 2.
Με ένα εναλλακτικό ή αποδοτικό πρόσημο, η διακύμανση του δείγματος προσδιορίζεται από τον τύπο
Dv \u003d w (1-w). (1.37)
Μπορεί να φανεί από τους τύπους (1.35) και (1.36) ότι το μέσο σφάλμα είναι μικρότερο για ένα μη επαναλαμβανόμενο δείγμα, γεγονός που καθορίζει την ευρύτερη εφαρμογή του.
Οριακό σφάλμα δειγματοληψίας
Λαμβάνοντας υπόψη ότι με βάση μια δειγματοληπτική έρευνα είναι αδύνατο να εκτιμηθεί με ακρίβεια η υπό μελέτη παράμετρος (για παράδειγμα, η μέση τιμή) του γενικού πληθυσμού, είναι απαραίτητο να βρεθούν τα όρια στα οποία βρίσκεται. Σε ένα συγκεκριμένο δείγμα, η διαφορά μπορεί να είναι μεγαλύτερη από, μικρότερη ή ίση με. Κάθε μία από τις αποκλίσεις από έχει μια ορισμένη πιθανότητα. Σε μια δειγματοληπτική έρευνα, η πραγματική αξία στον γενικό πληθυσμό είναι άγνωστη. Γνωρίζοντας το μέσο δειγματοληπτικό σφάλμα, με μια ορισμένη πιθανότητα είναι δυνατό να εκτιμηθεί η απόκλιση του μέσου όρου του δείγματος από τη γενική και να καθοριστούν τα όρια εντός των οποίων βρίσκεται η υπό μελέτη παράμετρος (στην περίπτωση αυτή, η μέση τιμή) στον γενικό πληθυσμό . Η απόκλιση του χαρακτηριστικού του δείγματος από το γενικό ονομάζεται οριακό δειγματοληπτικό σφάλμα.Καθορίζεται σε μετοχές μέσο σφάλμαΜε δεδομένη πιθανότητα, δηλ.
= t, (1.38)
όπου t - παράγοντας εμπιστοσύνης, ανάλογα με την πιθανότητα με την οποία προσδιορίζεται το οριακό δειγματοληπτικό σφάλμα.
Η πιθανότητα εμφάνισης ενός συγκεκριμένου δειγματοληπτικού σφάλματος βρίσκεται χρησιμοποιώντας θεωρήματα της θεωρίας πιθανοτήτων. Σύμφωνα με το θεώρημα του P. L. Chebyshev, με αρκετά μεγάλο μέγεθος δείγματος και περιορισμένη διακύμανση πληθυσμού, η πιθανότητα η διαφορά μεταξύ του μέσου όρου του δείγματος και του γενικού μέσου όρου να είναι αυθαίρετα μικρή είναι κοντά στο ένα:
Ο A. M. Lyapunov το απέδειξε αυτό ανεξάρτητα από τη φύση της κατανομής του γενικού πληθυσμού, με αύξηση του μεγέθους του δείγματος, η κατανομή πιθανότητας εμφάνισης μιας ή άλλης τιμής του μέσου όρου του δείγματος προσεγγίζει την κανονική κατανομή. Αυτό είναι το λεγόμενο θεώρημα κεντρικού ορίου. Επομένως, η πιθανότητα απόκλισης του μέσου όρου του δείγματος από τον γενικό μέσο όρο, δηλ. η πιθανότητα εμφάνισης ενός δεδομένου περιοριστικού σφάλματος υπακούει επίσης στον καθορισμένο νόμο και μπορεί να βρεθεί ως συνάρτηση του tχρησιμοποιώντας το ολοκλήρωμα πιθανότητας Laplace:

όπου είναι η κανονικοποιημένη απόκλιση του μέσου όρου του δείγματος από τον γενικό μέσο όρο.
Οι τιμές του ολοκληρώματος Laplace για διαφορετικά tυπολογίζεται και διατίθεται σε ειδικούς πίνακες, ένας συνδυασμός των οποίων χρησιμοποιείται ευρέως στις στατιστικές:
|
Πιθανότητα |
||||||||
Δεδομένου ενός συγκεκριμένου επιπέδου πιθανότητας, επιλέξτε την τιμή της κανονικοποιημένης απόκλισης tκαι προσδιορίστε το οριακό σφάλμα δειγματοληψίας με τον τύπο (1.38)
Σε αυτή την περίπτωση, = 0,95 και t= 1,96, δηλ. θεωρήστε ότι με πιθανότητα 95% το οριακό δειγματοληπτικό σφάλμα είναι διπλάσιο του μέσου όρου. Επομένως, στα στατιστικά, η αξία tμερικές φορές αναφέρεται ο συντελεστής πολλαπλότητας του οριακού σφάλματος σε σχέση με τον μέσο όρο.
Μετά τον υπολογισμό του οριακού σφάλματος, βρίσκεται το διάστημα εμπιστοσύνης του γενικευτικού χαρακτηριστικού του γενικού πληθυσμού. Ένα τέτοιο διάστημα για τον γενικό μέσο όρο έχει τη μορφή
(-) (+), (1.39)
και ομοίως για τη γενική μετοχή
(w-)p(w+). (1.40)
Κατά συνέπεια, κατά την επιλεκτική παρατήρηση, δεν προσδιορίζεται μία ακριβής τιμή του γενικευτικού χαρακτηριστικού του γενικού πληθυσμού, αλλά μόνο το διάστημα εμπιστοσύνης του με ένα δεδομένο επίπεδο πιθανότητας. Και αυτό είναι ένα σοβαρό μειονέκτημα της μεθόδου δειγματοληψίας των στατιστικών.
Προσδιορισμός του μεγέθους του δείγματος
Κατά την ανάπτυξη ενός προγράμματος επιλεκτικής παρατήρησης, μερικές φορές τους δίνεται μια συγκεκριμένη τιμή του οριακού σφάλματος με ένα επίπεδο πιθανότητας. Το ελάχιστο μέγεθος δείγματος που παρέχει τη δεδομένη ακρίβεια παραμένει άγνωστο. Μπορεί να ληφθεί από τους τύπους για τα μέσα και τα οριακά σφάλματα, ανάλογα με τον τύπο του δείγματος. Έτσι, αντικαθιστώντας τους τύπους πρώτα (1.35) και μετά (1.36) στον τύπο (1.38) και λύνοντάς τον σε σχέση με το μέγεθος του δείγματος, λαμβάνουμε τους ακόλουθους τύπους
για επαναδειγματοληψία
για μη επαναδειγματοληψία
Επιπλέον, για στατιστικές τιμές με ποσοτικά χαρακτηριστικά, πρέπει να γνωρίζουμε και τη διακύμανση του δείγματος, αλλά ούτε από την αρχή των υπολογισμών είναι γνωστή. Επομένως, λαμβάνεται περίπου με έναν από τους ακόλουθους τρόπους:
λαμβάνονται από προηγούμενες δειγματοληπτικές παρατηρήσεις·
σύμφωνα με τον κανόνα ότι το εύρος διακύμανσης ταιριάζει περίπου έξι τυπικές αποκλίσεις (R/ = 6 ή R/ = 6; από εδώ D = R 2 /36);
Σύμφωνα με τον κανόνα «τρία σίγμα», σύμφωνα με τον οποίο περίπου τρία τυπικές αποκλίσεις(/ =3; άρα = /3 ή D = 2 /9).
Κατά τη μελέτη μη αριθμητικών χαρακτηριστικών, ακόμη και αν δεν υπάρχουν κατά προσέγγιση πληροφορίες για το κλάσμα δείγματος, γίνεται αποδεκτό w= 0,5, το οποίο, σύμφωνα με τον τύπο (1,37), αντιστοιχεί στη διακύμανση του δείγματος στην ποσότητα Dv = 0,5(1-0,5) = 0,25.
Το κύριο πλεονέκτημα της δειγματοληψίας, μεταξύ άλλων, είναι η δυνατότητα υπολογισμού του τυχαίου δειγματοληπτικού σφάλματος.
Τα δειγματοληπτικά σφάλματα είναι είτε συστηματικά είτε τυχαία.
Συστηματικός- σε περίπτωση που παραβιαστεί η βασική αρχή της δειγματοληψίας - τυχαίας. Τυχαίος- συνήθως προκύπτουν λόγω του γεγονότος ότι η δομή του πληθυσμού του δείγματος διαφέρει πάντα από τη δομή του γενικού πληθυσμού, ανεξάρτητα από το πόσο σωστά γίνεται η επιλογή, δηλαδή, παρά την αρχή της τυχαίας επιλογής των πληθυσμιακών μονάδων, εξακολουθούν να υπάρχουν αποκλίσεις μεταξύ των χαρακτηριστικών του δείγματος και του γενικού πληθυσμού. Η μελέτη και η μέτρηση των τυχαίων σφαλμάτων αντιπροσωπευτικότητας είναι το κύριο καθήκον της μεθόδου δειγματοληψίας.
Κατά κανόνα, το σφάλμα του μέσου όρου και το σφάλμα της αναλογίας υπολογίζονται συχνότερα. Οι ακόλουθες συμβάσεις χρησιμοποιούνται στους υπολογισμούς:
Ο μέσος όρος υπολογίζεται στο γενικό πληθυσμό.
Ο μέσος όρος που υπολογίστηκε στον πληθυσμό του δείγματος.
R- το μερίδιο αυτής της ομάδας στο γενικό πληθυσμό.
w- το μερίδιο αυτής της ομάδας στον πληθυσμό του δείγματος.
Χρησιμοποιώντας συμβάσεις, τα δειγματοληπτικά σφάλματα για τον μέσο όρο και για το κλάσμα μπορούν να γραφούν ως εξής:
Ο μέσος όρος του δείγματος και η αναλογία του δείγματος είναι τυχαίες μεταβλητές που μπορούν να λάβουν οποιεσδήποτε τιμές ανάλογα με τις μονάδες του πληθυσμού που περιλαμβάνονται στο δείγμα. Επομένως, τα σφάλματα δειγματοληψίας είναι επίσης τυχαίες μεταβλητές και μπορούν να λάβουν διαφορετικές τιμές. Επομένως, ο μέσος όρος των πιθανών σφαλμάτων μ .
Σε αντίθεση με το συστηματικό, το τυχαίο σφάλμα μπορεί να προσδιοριστεί εκ των προτέρων, πριν από τη δειγματοληψία, σύμφωνα με τα οριακά θεωρήματα που λαμβάνονται υπόψη στις μαθηματικές στατιστικές.
Το μέσο σφάλμα προσδιορίζεται με πιθανότητα 0,683. Σε περίπτωση διαφορετικής πιθανότητας, μιλάμε για οριακό σφάλμα.
Το μέσο δειγματοληπτικό σφάλμα για τον μέσο όρο και για το κλάσμα ορίζεται ως εξής:
![]()
Σε αυτούς τους τύπους, η διακύμανση ενός χαρακτηριστικού είναι χαρακτηριστικό του γενικού πληθυσμού, οι οποίοι είναι άγνωστοι κατά την επιλεκτική παρατήρηση. Στην πράξη, αντικαθίστανται από παρόμοια χαρακτηριστικά του πληθυσμού του δείγματος με βάση το νόμο των μεγάλων αριθμών, σύμφωνα με τον οποίο ο πληθυσμός δείγματος μεγάλου όγκου αναπαράγει με ακρίβεια τα χαρακτηριστικά του γενικού πληθυσμού.
Τύποι για τον προσδιορισμό του μέσου σφάλματος για διάφορες μεθόδους επιλογής:
| Μέθοδος επιλογής | Αλλεπάλληλος | μη επαναλαμβανόμενο | ||
| μέσο σφάλμα | σφάλμα κοινής χρήσης | μέσο σφάλμα | σφάλμα κοινής χρήσης | |
| Αυτοτυχαίο και μηχανικό | |
|||
| Τυπικός | |
|||
| Κατα συρροη |
μ - μέσο σφάλμα?
Δ - οριακό σφάλμα.
Π -το μέγεθος του δείγματος;
Ν-το μέγεθος του γενικού πληθυσμού·
Συνολική διακύμανση;
w-μερίδιο αυτής της κατηγορίας στο συνολικό μέγεθος του δείγματος:
Μέσος όρος διακύμανσης εντός της ομάδας.
Δ 2 - διασπορά μεταξύ ομάδων.
r-αριθμός σειρών στο δείγμα·
Rείναι ο συνολικός αριθμός των επεισοδίων.
οριακό σφάλμαγια όλες τις μεθόδους επιλογής σχετίζεται με το μέσο δειγματοληπτικό σφάλμα ως εξής:
όπου t- συντελεστής εμπιστοσύνης, λειτουργικά συνδεδεμένος με την πιθανότητα με την οποία παρέχεται η τιμή του οριακού σφάλματος. Ανάλογα με την πιθανότητα, ο συντελεστής εμπιστοσύνης t παίρνει τις ακόλουθες τιμές:
| t | Π |
| 0,683 | |
| 1,5 | 0,866 |
| 2,0 | 0,954 |
| 2,5 | 0,988 |
| 3,0 | 0,997 |
| 4,0 | 0,9999 |
Για παράδειγμα, η πιθανότητα σφάλματος είναι 0,683. Αυτό σημαίνει ότι ο γενικός μέσος όρος διαφέρει από τον μέσο όρο του δείγματος σε απόλυτη τιμή όχι περισσότερο από μ με πιθανότητα 0,683, τότε αν είναι ο μέσος όρος του δείγματος, είναι ο γενικός μέσος όρος, τότε Μεπιθανότητα 0,683.
Εάν θέλουμε να παράσχουμε μεγαλύτερη πιθανότητα συμπερασμάτων, αυξάνουμε έτσι τα όρια του τυχαίου λάθους.
Έτσι, η τιμή του οριακού σφάλματος εξαρτάται από τις ακόλουθες ποσότητες:
Η διακύμανση του πρόσημου (άμεση σύνδεση), η οποία χαρακτηρίζεται από το μέγεθος της διασποράς.
Μεγέθη δειγμάτων (ανατροφοδότηση).
Πιθανότητα εμπιστοσύνης (άμεση σύνδεση).
μέθοδος επιλογής.
Ένα παράδειγμα υπολογισμού του σφάλματος του μέσου όρου και του σφάλματος της μετοχής.
Για τον προσδιορισμό του μέσου αριθμού παιδιών σε μια οικογένεια, επιλέχθηκαν 100 οικογένειες από 1000 οικογένειες με τυχαία μη επαναλαμβανόμενη δειγματοληψία. Τα αποτελέσματα φαίνονται στον πίνακα:
Καθορίζω:.
- με πιθανότητα 0,997, το οριακό δειγματοληπτικό σφάλμα και τα όρια εντός των οποίων βρίσκεται ο μέσος αριθμός παιδιών σε μια οικογένεια.
- με πιθανότητα 0,954, τα όρια στα οποία εντοπίζεται η αναλογία των οικογενειών με δύο παιδιά.
1. Προσδιορίστε το οριακό σφάλμα του μέσου όρου με πιθανότητα 0,977. Για να απλοποιήσουμε τους υπολογισμούς, χρησιμοποιούμε τη μέθοδο των ροπών:
![]()

Π = 0,997 t= 3
![]()
μέσο σφάλμα του μέσου όρου, 0,116 - οριακό σφάλμα
2,12 – 0,116 ≤ ≤ 2,12+ 0,116
2,004 ≤ ≤ 2,236
Κατά συνέπεια, με πιθανότητα 0,997, ο μέσος όρος των παιδιών σε μια οικογένεια στο γενικό πληθυσμό, δηλαδή μεταξύ 1000 οικογενειών, κυμαίνεται μεταξύ 2.004 - 2.236.
Η έννοια και ο υπολογισμός του δειγματοληπτικού σφάλματος.
Το καθήκον της επιλεκτικής παρατήρησης είναι να δώσει σωστές ιδέες για τους συνοπτικούς δείκτες ολόκληρου του πληθυσμού με βάση κάποιο μέρος τους που υποβλήθηκε σε παρατήρηση. Η πιθανή απόκλιση του μεριδίου δείγματος και του μέσου όρου του δείγματος από το μερίδιο και το μέσο όρο στο γενικό πληθυσμό ονομάζεται σφάλμα δειγματοληψίας ή σφάλμα αντιπροσωπευτικότητας. Όσο μεγαλύτερη είναι η τιμή αυτού του σφάλματος, τόσο περισσότερο διαφέρουν οι δείκτες παρατήρησης του δείγματος από εκείνους του γενικού πληθυσμού.
Διαφέρω:
Σφάλματα δειγματοληψίας.
Σφάλματα εγγραφής.
Σφάλματα εγγραφήςσυμβαίνουν όταν ένα γεγονός διαπιστώνεται εσφαλμένα στη διαδικασία παρατήρησης. Είναι χαρακτηριστικά τόσο της συνεχούς παρατήρησης όσο και της επιλεκτικής παρατήρησης, αλλά είναι λιγότερο στην επιλεκτική παρατήρηση.
Η φύση του σφάλματος είναι:
Τεντενιστικός - εσκεμμένος, δηλ. επιλέχθηκαν είτε οι καλύτερες είτε οι χειρότερες μονάδες του πληθυσμού. Σε αυτή την περίπτωση, οι παρατηρήσεις χάνουν το νόημά τους.
Τυχαία - η κύρια οργανωτική αρχή της επιλεκτικής παρατήρησης είναι η αποτροπή της σκόπιμης επιλογής, δηλ. διασφαλίζει την αυστηρή τήρηση της αρχής της τυχαίας επιλογής.
Γενικός κανόνας τυχαίας επιλογήςείναι: μεμονωμένες μονάδες του γενικού πληθυσμού πρέπει να έχουν ακριβώς τις ίδιες συνθήκες και ευκαιρίες για να εμπίπτουν στον αριθμό των μονάδων που περιλαμβάνονται στο δείγμα. Αυτό χαρακτηρίζει την ανεξαρτησία του αποτελέσματος του δείγματος από τη βούληση του παρατηρητή. Η βούληση του παρατηρητή δημιουργεί τετριμμένα λάθη. Το σφάλμα δειγματοληψίας στην τυχαία επιλογή είναι τυχαίο. Χαρακτηρίζει το μέγεθος των αποκλίσεων των γενικών χαρακτηριστικών από τα δείγματα.
Λόγω του γεγονότος ότι τα χαρακτηριστικά στον υπό μελέτη πληθυσμό ποικίλλουν, η σύνθεση των μονάδων στο δείγμα μπορεί να μην συμπίπτει με τη σύνθεση των μονάδων ολόκληρου του πληθυσμού. Αυτό σημαίνει ότι Rκαι δεν ταιριάζουν με Wκαι . Η πιθανή απόκλιση μεταξύ αυτών των χαρακτηριστικών καθορίζεται από το σφάλμα δειγματοληψίας, το οποίο καθορίζεται από τον τύπο:
πού είναι η γενική απόκλιση.
πού είναι η διακύμανση του δείγματος.
Αυτό δείχνει πού διαφέρει η γενική διακύμανση από τη διακύμανση του δείγματος σε χρόνους.
Υπάρχει επαναλαμβανόμενη και μη επαναλαμβανόμενη επιλογή. Η ουσία της επανεπιλογής είναι ότι κάθε μονάδα του δείγματος, μετά από παρατήρηση, επιστρέφει στον γενικό πληθυσμό και μπορεί να επανεξεταστεί. Κατά την επαναδειγματοληψία, υπολογίζεται το μέσο σφάλμα δειγματοληψίας:
Για τον δείκτη του μεριδίου ενός εναλλακτικού χαρακτηριστικού, η διακύμανση του δείγματος προσδιορίζεται από τον τύπο:
Στην πράξη, η επανεπιλογή χρησιμοποιείται σπάνια. Με μη επαναλαμβανόμενη επιλογή, το μέγεθος του γενικού πληθυσμού Νμειώνεται κατά τη δειγματοληψία, ο τύπος για το μέσο δειγματοληπτικό σφάλμα για ένα ποσοτικό χαρακτηριστικό είναι:
Μία από τις πιθανές τιμές στις οποίες μπορεί να είναι το μερίδιο του υπό μελέτη γνωρίσματος είναι ίση με:
όπου είναι το σφάλμα δειγματοληψίας του εναλλακτικού χαρακτηριστικού.
Παράδειγμα.
Κατά τη διάρκεια μιας δειγματοληπτικής έρευνας του 10% των προϊόντων μιας παρτίδας τελικών προϊόντων σύμφωνα με τη μέθοδο χωρίς επανεπιλογή, ελήφθησαν τα ακόλουθα δεδομένα για την περιεκτικότητα σε υγρασία στα δείγματα.
Προσδιορίστε τη μέση υγρασία %, διακύμανση, τυπική απόκλιση, με πιθανότητα 0,954, τα πιθανά όρια στα οποία αναμένεται ο μέσος όρος. % υγρασία όλων των τελικών προϊόντων, με πιθανότητα 0,987, πιθανά όρια ειδικού βάρους τυπικών προϊόντων, με την προϋπόθεση ότι τα προϊόντα με περιεκτικότητα σε υγρασία έως 13 και άνω του 19% ανήκουν σε μη τυποποιημένη παρτίδα.
Μόνο με μια ορισμένη πιθανότητα μπορεί να υποστηριχθεί ότι το γενικό μερίδιο του δείγματος και ο γενικός μέσος όρος του δείγματος αποκλίνουν σε tμια φορά.
Στη στατιστική, αυτές οι αποκλίσεις ονομάζονται οριακά δειγματοληπτικά σφάλματα και σημειώνονται.
Η πιθανότητα κρίσεων μπορεί να αυξηθεί ή να μειωθεί tμια φορά. Με πιθανότητα 0,683, με 0,954, με 0,987, τότε προσδιορίζονται οι δείκτες του γενικού πληθυσμού σύμφωνα με τους δείκτες του δείγματος:
Αντιπροσωπεύει μια τέτοια απόκλιση μεταξύ των μέσων όρων του δείγματος και του γενικού πληθυσμού, η οποία δεν υπερβαίνει το ± b (δέλτα).
Με βάση Τα θεωρήματα του P. L. Chebyshev μέση τιμή σφάλματοςσε περίπτωση τυχαίας επανεπιλογής, υπολογίζεται με τον τύπο (για ένα μέσο ποσοτικό χαρακτηριστικό):
όπου ο αριθμητής είναι η διακύμανση του χαρακτηριστικού x στο δείγμα.
n είναι το μέγεθος του δείγματος.
Για ένα εναλλακτικό χαρακτηριστικό, ο τύπος για το μέσο δειγματοληπτικό σφάλμα για την αναλογία σύμφωνα με το θεώρημα του J. Bernoulliυπολογίζεται με τον τύπο:

όπου p(1 - p) είναι η διακύμανση του μεριδίου του χαρακτηριστικού στον γενικό πληθυσμό.
n - μέγεθος δείγματος.
Λόγω του γεγονότος ότι η διακύμανση του χαρακτηριστικού στον γενικό πληθυσμό δεν είναι ακριβώς γνωστή, στην πράξη χρησιμοποιείται η τιμή διακύμανσης, η οποία υπολογίζεται για τον πληθυσμό του δείγματος με βάση νόμος των μεγάλων αριθμών. Σύμφωνα με αυτόν τον νόμο, με μεγάλο μέγεθος δείγματος, το δείγμα αναπαράγει με ακρίβεια τα χαρακτηριστικά του γενικού πληθυσμού.
Επομένως, οι τύποι υπολογισμού μέσο σφάλμα στην τυχαία επαναδειγματοληψία θα μοιάζει με αυτό:
1. Για ένα μέσο ποσοτικό χαρακτηριστικό:

όπου S^2 είναι η διακύμανση του χαρακτηριστικού x στο δείγμα.
n - μέγεθος δείγματος.

όπου w (1 - w) είναι η διακύμανση της αναλογίας του υπό μελέτη χαρακτηριστικού στον πληθυσμό του δείγματος.
Στη θεωρία πιθανοτήτων, αποδείχθηκε ότι εκφράζεται μέσω του δείγματος σύμφωνα με τον τύπο:
![]()
Σε περιπτώσεις μικρό δείγμα, όταν ο όγκος του είναι μικρότερος από 30, είναι απαραίτητο να ληφθεί υπόψη ο συντελεστής n/(n-1). Στη συνέχεια, το μέσο σφάλμα ενός μικρού δείγματος υπολογίζεται από τον τύπο:

Δεδομένου ότι ο αριθμός των μονάδων του γενικού πληθυσμού μειώνεται στη διαδικασία της μη επαναλαμβανόμενης δειγματοληψίας, στους παραπάνω τύπους για τον υπολογισμό των μέσων σφαλμάτων δειγματοληψίας, η έκφραση ρίζας πρέπει να πολλαπλασιαστεί με 1- (n / N).
Οι τύποι υπολογισμού για αυτόν τον τύπο δείγματος θα μοιάζουν με αυτό:
1. Για το μέσο ποσοτικό χαρακτηριστικό:
όπου N είναι ο όγκος του γενικού πληθυσμού. n - μέγεθος δείγματος.
2. Για μια μετοχή (εναλλακτική δυνατότητα):

όπου 1- (n/N) είναι η αναλογία των μονάδων στο γενικό πληθυσμό που δεν συμπεριλήφθηκαν στο δείγμα.
Εφόσον το n είναι πάντα μικρότερο από το Ν, ο πρόσθετος παράγοντας 1 - (n/N) θα είναι πάντα μικρότερος από ένα. Αυτό σημαίνει ότι το μέσο σφάλμα για μη επαναλαμβανόμενη επιλογή θα είναι πάντα μικρότερο από ό,τι για επαναλαμβανόμενη επιλογή. Όταν η αναλογία των μονάδων στο γενικό πληθυσμό που δεν συμπεριλήφθηκαν στο δείγμα είναι σημαντική, τότε η τιμή 1 - (n / N) είναι κοντά στο ένα και, στη συνέχεια, το μέσο σφάλμα υπολογίζεται σύμφωνα με τον γενικό τύπο.
Το μέσο σφάλμα εξαρτάται από τους ακόλουθους παράγοντες:
1. Όταν πληρούται η αρχή της τυχαίας επιλογής, το μέσο δειγματοληπτικό σφάλμα προσδιορίζεται, πρώτον, από το μέγεθος του δείγματος: όσο μεγαλύτερος είναι ο αριθμός, τόσο μικρότερες είναι οι τιμές μέσο δειγματοληπτικό σφάλμα. Ο γενικός πληθυσμός χαρακτηρίζεται με μεγαλύτερη ακρίβεια όταν περισσότερες μονάδες αυτού του πληθυσμού καλύπτουν τη δειγματοληπτική παρατήρηση
2. Το μέσο σφάλμα εξαρτάται επίσης από τον βαθμό διακύμανσης των χαρακτηριστικών. Ο βαθμός διακύμανσης χαρακτηρίζεται από . Όσο μικρότερη είναι η διακύμανση χαρακτηριστικών (διασπορά), τόσο μικρότερο είναι το μέσο σφάλμα δειγματοληψίας. Με μηδενική διακύμανση (το χαρακτηριστικό δεν μεταβάλλεται), το μέσο δειγματοληπτικό σφάλμα είναι μηδέν, επομένως οποιαδήποτε μονάδα του γενικού πληθυσμού θα χαρακτηρίζει ολόκληρο τον πληθυσμό σύμφωνα με αυτό το χαρακτηριστικό.
Τα λάθη είναι συστηματικά και τυχαία
Αρθρωτή μονάδα 2 Σφάλματα δειγματοληψίας
Δεδομένου ότι το δείγμα καλύπτει συνήθως ένα πολύ μικρό μέρος του πληθυσμού, θα πρέπει να υποτεθεί ότι θα υπάρχουν διαφορές μεταξύ της εκτίμησης και του χαρακτηριστικού του πληθυσμού που αντικατοπτρίζει αυτή η εκτίμηση. Αυτές οι διαφορές ονομάζονται σφάλματα εμφάνισης ή σφάλματα αντιπροσωπευτικότητας. Τα σφάλματα αντιπροσωπευτικότητας ταξινομούνται σε δύο τύπους: συστηματικά και τυχαία.
Συστηματικά λάθη- πρόκειται για συνεχή υπερεκτίμηση ή υποεκτίμηση της αξίας της εκτίμησης σε σύγκριση με τα χαρακτηριστικά του γενικού πληθυσμού. Ο λόγος για την εμφάνιση ενός συστηματικού λάθους είναι η μη τήρηση της αρχής της ισοπιθανότητας εισαγωγής κάθε μονάδας του γενικού πληθυσμού στο δείγμα, δηλαδή το δείγμα σχηματίζεται από κυρίως «χειρότερους» (ή «καλύτερους») εκπροσώπους. του γενικού πληθυσμού. Η συμμόρφωση με την αρχή της ίσης πιθανότητας κάθε μονάδας να εισέλθει στο δείγμα καθιστά δυνατή την πλήρη εξάλειψη αυτού του τύπου σφάλματος.
Τυχαία σφάλματα -Πρόκειται για διαφορές μεταξύ της εκτίμησης και του εκτιμώμενου χαρακτηριστικού του γενικού πληθυσμού, οι οποίες διαφέρουν από δείγμα σε δείγμα ως προς το πρόσημο και το μέγεθος. Ο λόγος για την εμφάνιση τυχαίων σφαλμάτων είναι το παιχνίδι της τύχης στη διαμόρφωση ενός δείγματος που είναι μόνο ένα μέρος του γενικού πληθυσμού. Αυτός ο τύπος σφάλματος είναι εγγενής στη μέθοδο δειγματοληψίας. Είναι αδύνατο να τα εξαιρέσουμε εντελώς, το καθήκον είναι να προβλέψουμε το πιθανό μέγεθός τους και να τα μειώσουμε στο ελάχιστο. Η σειρά των ενεργειών που σχετίζονται με αυτό προκύπτει από την εξέταση τριών τύπων τυχαίων σφαλμάτων: συγκεκριμένο, μεσαίο και ακραίο.
2.2.1 Ειδικάσφάλμα είναι το σφάλμα ενός δείγματος που λήφθηκε. Εάν ο μέσος όρος για αυτό το δείγμα () είναι μια εκτίμηση για τον γενικό μέσο όρο (0) και, υποθέτοντας ότι αυτός ο γενικός μέσος όρος είναι γνωστός σε εμάς, τότε η διαφορά = -0 και θα είναι το ειδικό σφάλμα αυτού του δείγματος. Εάν επαναλάβουμε το δείγμα από αυτόν τον γενικό πληθυσμό πολλές φορές, τότε κάθε φορά παίρνουμε μια νέα τιμή ενός συγκεκριμένου σφάλματος: ..., και ούτω καθεξής. Σχετικά με αυτά τα συγκεκριμένα σφάλματα, μπορούμε να πούμε τα εξής: ορισμένα από αυτά θα συμπίπτουν σε μέγεθος και πρόσημο, δηλαδή υπάρχει κατανομή σφαλμάτων, μερικά από αυτά θα είναι ίσα με 0, υπάρχει σύμπτωση της εκτίμησης και της παραμέτρου του γενικού πληθυσμού·
2.2.2 Μέσο σφάλμαείναι η ρίζα του μέσου τετραγώνου όλων των συγκεκριμένων σφαλμάτων εκτίμησης που είναι δυνατά κατά τύχη: , πού είναι η τιμή των μεταβαλλόμενων συγκεκριμένων σφαλμάτων; συχνότητα (πιθανότητα) εμφάνισης συγκεκριμένου σφάλματος. Το μέσο σφάλμα δείγματος δείχνει πόσο σφάλμα μπορεί να γίνει κατά μέσο όρο εάν, με βάση την εκτίμηση, γίνει μια κρίση σχετικά με την παράμετρο του γενικού πληθυσμού. Ο παραπάνω τύπος αποκαλύπτει το περιεχόμενο του μέσου σφάλματος, αλλά δεν μπορεί να χρησιμοποιηθεί για πρακτικούς υπολογισμούς, μόνο και μόνο επειδή προϋποθέτει γνώση της παραμέτρου του γενικού πληθυσμού, η οποία από μόνη της αποκλείει την ανάγκη δειγματοληψίας.
Οι πρακτικοί υπολογισμοί του μέσου σφάλματος της εκτίμησης βασίζονται στην προϋπόθεση ότι αυτό (το μέσο σφάλμα) είναι ουσιαστικά η τυπική απόκλιση όλων των πιθανών τιμών της εκτίμησης. Αυτή η υπόθεση καθιστά δυνατή τη λήψη αλγορίθμων για τον υπολογισμό του μέσου σφάλματος με βάση τα δεδομένα ενός μόνο δείγματος. Ειδικότερα, το μέσο σφάλμα του μέσου όρου του δείγματος μπορεί να καθοριστεί με βάση το ακόλουθο σκεπτικό. Υπάρχει μια επιλογή (,… ) που αποτελείται από μονάδες. Για το δείγμα, ο μέσος όρος του δείγματος προσδιορίζεται ως εκτίμηση του γενικού μέσου όρου. Κάθε τιμή (,… ) κάτω από το πρόσημο του αθροίσματος θα πρέπει να θεωρείται ως ανεξάρτητη τυχαία μεταβλητή, αφού η πρώτη, η δεύτερη κ.λπ. οι μονάδες μπορούν να λάβουν οποιαδήποτε από τις τιμές που υπάρχουν στον γενικό πληθυσμό. Επομένως Εφόσον, όπως είναι γνωστό, η διακύμανση του αθροίσματος των ανεξάρτητων τυχαίων μεταβλητών είναι ίση με το άθροισμα των διακυμάνσεων, τότε . Συνεπάγεται ότι το μέσο σφάλμα για τη μέση τιμή του δείγματος θα είναι ίσο και σχετίζεται αντιστρόφως με το μέγεθος του δείγματος (μέσω της τετραγωνικής ρίζας του) και σε ευθεία αναλογία με την τυπική απόκλιση του χαρακτηριστικού στο γενικό πληθυσμό. Αυτό είναι λογικό, αφού ο μέσος όρος του δείγματος είναι μια συνεπής εκτίμηση για τον γενικό μέσο όρο και, καθώς αυξάνεται το μέγεθος του δείγματος, προσεγγίζει στην τιμή του την εκτιμώμενη παράμετρο του γενικού πληθυσμού. Η άμεση εξάρτηση του μέσου σφάλματος από τη μεταβλητότητα του χαρακτηριστικού οφείλεται στο γεγονός ότι όσο μεγαλύτερη είναι η μεταβλητότητα του χαρακτηριστικού στο γενικό πληθυσμό, τόσο πιο δύσκολο είναι να δημιουργηθεί ένα κατάλληλο μοντέλο του γενικού πληθυσμού με βάση το δείγμα. Στην πράξη, η τυπική απόκλιση ενός χαρακτηριστικού στον γενικό πληθυσμό αντικαθίσταται από την εκτίμησή του για το δείγμα και στη συνέχεια ο τύπος για τον υπολογισμό του μέσου σφάλματος του μέσου όρου του δείγματος γίνεται:, ενώ λαμβάνεται υπόψη η μεροληψία της διακύμανσης του δείγματος Η τυπική απόκλιση δείγματος υπολογίζεται με τον τύπο = . Επειδή το σύμβολο n υποδηλώνει το μέγεθος του δείγματος. , τότε ο παρονομαστής κατά τον υπολογισμό της τυπικής απόκλισης δεν πρέπει να χρησιμοποιεί το μέγεθος του δείγματος (n), αλλά τον λεγόμενο αριθμό βαθμών ελευθερίας (n-1). Ο αριθμός των βαθμών ελευθερίας νοείται ως ο αριθμός των μονάδων στο σύνολο, ο οποίος μπορεί ελεύθερα να ποικίλει (αλλάζει) εάν ορίζεται κάποιο χαρακτηριστικό στο σύνολο. Στην περίπτωσή μας, εφόσον προσδιορίζεται ο μέσος όρος του δείγματος, οι μονάδες μπορούν να ποικίλλουν ελεύθερα.
Ο Πίνακας 2.2 παρέχει τύπους για τον υπολογισμό των μέσων σφαλμάτων διαφόρων εκτιμήσεων δειγμάτων. Όπως φαίνεται από αυτόν τον πίνακα, η τιμή του μέσου σφάλματος για όλες τις εκτιμήσεις σχετίζεται αντιστρόφως με το μέγεθος του δείγματος και σε άμεση σχέση με τη μεταβλητότητα. Αυτό μπορεί επίσης να ειπωθεί για το μέσο σφάλμα του κλάσματος δείγματος (συχνότητα). Κάτω από τη ρίζα βρίσκεται η διακύμανση του εναλλακτικού χαρακτηριστικού, που καθορίζεται από το δείγμα ()
Οι τύποι που δίνονται στον Πίνακα 2.2 αναφέρονται στη λεγόμενη τυχαία, επαναλαμβανόμενη επιλογή των μονάδων στο δείγμα. Με άλλες μεθόδους επιλογής, οι οποίες θα συζητηθούν παρακάτω, οι τύποι θα τροποποιηθούν κάπως.
Πίνακας 2.2
Τύποι για τον υπολογισμό των μέσων σφαλμάτων των δειγματοληπτικών εκτιμήσεων
2.2.3 Οριακό σφάλμα δειγματοληψίαςΗ γνώση της εκτίμησης και του μέσου λάθους της είναι σε ορισμένες περιπτώσεις εντελώς ανεπαρκής. Για παράδειγμα, όταν χρησιμοποιούνται ορμόνες στη διατροφή των ζώων, η γνώση μόνο του μέσου μεγέθους των μη αποσυντιθέμενων επιβλαβών υπολειμμάτων τους και του μέσου λάθους σημαίνει έκθεση των καταναλωτών του προϊόντος σε σοβαρό κίνδυνο. Εδώ η ανάγκη καθορισμού του μέγιστου ( οριακό σφάλμα). Όταν χρησιμοποιείται η μέθοδος δειγματοληψίας, το οριακό σφάλμα δεν ορίζεται με τη μορφή συγκεκριμένης τιμής, αλλά με τη μορφή ίσων ορίων
(διαστήματα) προς οποιαδήποτε κατεύθυνση από την τιμή αξιολόγησης.
Ο προσδιορισμός των ορίων του οριακού σφάλματος βασίζεται στα χαρακτηριστικά της κατανομής συγκεκριμένων σφαλμάτων. Για τα λεγόμενα μεγάλα δείγματα, ο αριθμός των οποίων είναι πάνω από 30 μονάδες () , τα συγκεκριμένα σφάλματα κατανέμονται σύμφωνα με κανονικός νόμοςδιανομή; με μικρά δείγματα () διανέμονται συγκεκριμένα σφάλματα σύμφωνα με τον νόμο διανομής Gosset
(Μαθητης σχολειου). Όπως εφαρμόζεται σε συγκεκριμένα σφάλματα στο δείγμα σημαίνει, η συνάρτηση κανονική κατανομήέχει τη μορφή: , όπου είναι η πυκνότητα πιθανότητας εμφάνισης ορισμένων τιμών, με την προϋπόθεση ότι, όπου βρίσκονται τα μέσα του δείγματος. - γενικός μέσος όρος, - μέσος όρος σφάλματος για το μέσο όρο του δείγματος. Δεδομένου ότι το μέσο σφάλμα () είναι μια σταθερή τιμή, τότε, σύμφωνα με τον κανονικό νόμο, κατανέμονται συγκεκριμένα σφάλματα, που εκφράζονται σε κλάσματα του μέσου σφάλματος ή στις λεγόμενες κανονικοποιημένες αποκλίσεις.
Λαμβάνοντας το ολοκλήρωμα της συνάρτησης κανονικής κατανομής, μπορεί κανείς να καθορίσει την πιθανότητα ότι το σφάλμα θα περικλείεται σε ένα ορισμένο διάστημα μεταβολής του t και την πιθανότητα ότι το σφάλμα θα υπερβεί αυτό το διάστημα (το αντίστροφο γεγονός). Για παράδειγμα, η πιθανότητα το σφάλμα να μην υπερβαίνει το μισό του μέσου όρου του σφάλματος (και στις δύο κατευθύνσεις από τον γενικό μέσο όρο) είναι 0,3829, ότι το σφάλμα θα περιέχεται σε ένα μέσο σφάλμα - 0,6827, 2 κατά μέσο όρο σφάλματα - 0,9545 κ.ο.κ.
Η σχέση μεταξύ του επιπέδου πιθανότητας και του διαστήματος μεταβολής t (και, τελικά, του διαστήματος μεταβολής του σφάλματος) μας επιτρέπει να προσεγγίσουμε τον ορισμό του διαστήματος (ή των ορίων) του οριακού σφάλματος, συνδέοντας την τιμή του με την πιθανότητα Η πιθανότητα υλοποίησης είναι η πιθανότητα το σφάλμα να είναι σε κάποιο διάστημα. Η πιθανότητα υλοποίησης θα είναι «εμπιστοσύνη» στην περίπτωση που το αντίθετο συμβάν (το σφάλμα θα είναι εκτός του διαστήματος) έχει τέτοια πιθανότητα να συμβεί που μπορεί να αγνοηθεί. Επομένως, το επίπεδο εμπιστοσύνης της πιθανότητας ορίζεται, κατά κανόνα, όχι χαμηλότερο από 0,90 (η πιθανότητα του αντίθετου γεγονότος είναι 0,10). Περισσότερο αρνητικές επιπτώσειςέχει την εμφάνιση σφαλμάτων εκτός του καθορισμένου διαστήματος, τόσο υψηλότερο θα πρέπει να είναι το επίπεδο εμπιστοσύνης της πιθανότητας (0,95; 0,99; 0,999 και ούτω καθεξής).
Έχοντας επιλέξει το επίπεδο εμπιστοσύνης της πιθανότητας από τον πίνακα του ολοκληρώματος πιθανότητας της κανονικής κατανομής, θα πρέπει να βρείτε την αντίστοιχη τιμή του t και, στη συνέχεια, χρησιμοποιώντας την έκφραση = προσδιορίστε το διάστημα του οριακού σφάλματος . Η σημασία της λαμβανόμενης τιμής είναι η εξής: με το αποδεκτό επίπεδο εμπιστοσύνης πιθανότητας, το οριακό σφάλμα του μέσου όρου του δείγματος δεν θα υπερβαίνει το .
Για τον καθορισμό οριακών ορίων σφάλματος με βάση μεγάλα δείγματα για άλλες εκτιμήσεις (διακύμανση, τυπική απόκλιση, μερίδια κ.λπ.), χρησιμοποιείται η παραπάνω προσέγγιση, λαμβάνοντας υπόψη το γεγονός ότι χρησιμοποιείται διαφορετικός αλγόριθμος για τον προσδιορισμό του μέσου σφάλματος για κάθε εκτίμηση. .
Όσον αφορά τα μικρά δείγματα (), όπως ήδη αναφέρθηκε, η κατανομή των σφαλμάτων εκτίμησης αντιστοιχεί σε αυτή την περίπτωση στην κατανομή του t - Student. Η ιδιαιτερότητα αυτής της κατανομής είναι ότι μαζί με το σφάλμα περιέχει ως παράμετρο το μέγεθος του δείγματος ή μάλλον όχι το μέγεθος του δείγματος, αλλά τον αριθμό των βαθμών ελευθερίας.Με αύξηση του μεγέθους του δείγματος, το t-Student Η κατανομή προσεγγίζει την κανονική και στο , αυτές οι κατανομές πρακτικά συμπίπτουν. Συγκρίνοντας τις τιμές των t-Student και t - κανονικής κατανομής με την ίδια πιθανότητα εμπιστοσύνης, μπορούμε να πούμε ότι η τιμή του t-Student είναι πάντα μεγαλύτερη από την t-κανονική κατανομή και οι διαφορές αυξάνονται με τη μείωση του μεγέθους του δείγματος και με αύξηση του επιπέδου εμπιστοσύνης της πιθανότητας. Κατά συνέπεια, όταν χρησιμοποιούνται μικρά δείγματα, υπάρχουν μεγαλύτερα περιθώρια οριακού σφάλματος σε σύγκριση με μεγάλα δείγματα, και αυτά τα όρια διευρύνονται με μείωση του μεγέθους του δείγματος και αύξηση του επιπέδου εμπιστοσύνης της πιθανότητας.